Low performance and congestion: Why connecting your database via Serverless can be dangerous
I’m a Web Architect with 25 years of experience building web applications, and over the last two years, I’ve specialized in database optimization—becoming a well-known Supabase consultant along the way.
Recently, I worked with a client to boost their application’s performance and secure their infrastructure against data leaks and attacks.
A couple of weeks ago, that client ran into what looked like an attack—but wasn’t. Instead, it was just a burst of legitimate traffic. Harmless in theory, but it completely froze their entire app.
The surprising part? They hadn’t done anything obviously wrong. They followed the official best practices for connecting to their database. But those “best practices” ended up making the system unresponsive under real-world load.
Curious to get to the bottom of this, I took a deep dive into how serverless functions—especially under Vercel Fluid Compute—actually handle database connections.
This post is a practical guide for anyone connecting a Postgres database to a serverless environment. It covers what works, what definitely doesn’t, and why this isn’t just a corner case but a common pitfall.
Note: I use Vercel as the main example here, since that’s where I ran most of my tests. But these issues typically apply to other serverless providers, too.
Connecting to the db is easy, is it?
Let’s start with a classic scenario:
“I have a database and want to connect my ORM to it.”
Seems simple, right?
I head to the Drizzle docs (though you don’t need Drizzle specifically) and since I’m using Supabase (which is just Postgres under the hood), I open the Drizzle Supabase section to find this simple connection code:
import postgres from 'postgres';
const client = postgres(process.env.DATABASE_URL!);Looks clean and works… well, sort of. The catch? This approach can quietly throttle your app’s scalability. Let’s dig into why.
About database connections
Your database has a specific connection limit. In Postgres, you can view the global connection limit with:
SHOW max_connections;In my Supabase instance, that’s 60 total. You can find Supabase’s general connection limits here: https://supabase.com/docs/guides/troubleshooting/how-to-change-max-database-connections-_BQ8P5
This means my database can handle up to 60 total connections (which in Supabase includes internal connections as part of those 60). You can also set connection constraints for different users, but let’s focus on the essential topic of connection handling.
You can monitor active connections by running this query in your database:
SELECT pid,
usename,
datname,
client_addr,
application_name,
backend_start,
state,
state_change,
query
FROM pg_stat_activity
ORDER BY backend_start;In the results, usename shows the username for each connection (typically postgres unless you connect with a specific database user).
Every time your code opens a new connection, that’s one less slot available. So, if 60 users all load your site at the same moment and your app opens a fresh connection for each, you’re done: no new connections can be made until some close. All new requests fail.
Now, in theory, if your app never gets more than, say, 30 concurrent users, and each connection is opened and closed quickly, you’d be fine. But what happens when traffic spikes to 100 concurrent users? Boom—connection exhaustion.
Theory: Avoiding connection exhaustion with Pooling in your code
If your app runs on a persistent Node.js server (like a traditional backend or self-hosted Next.js app), there’s a well-known solution: connection pooling.
Instead of opening a new connection for every request, you keep a small “pool” of open connections and reuse them. This lets your app serve many users without overwhelming the database.
The good news: postgres library can handle this automatically:
import postgres from 'postgres';
export const sql = postgres(process.env.DATABASE_URL!);
sql`SELECT * FROM my_table`;It automatically connects and maintains a connection pool, defaulting to 10 connections (postgres(connectionString, { max: 10 })).
For our Supabase instance, if we only use database connections (not the Data API), we could set max: 40 to reserve 20 connections for internal processes. The postgres library can then manage up to 40 connections and queue queries until a connection becomes available. This should work seamlessly.
And it does work when running on a persistent server and importing the sql function throughout your codebase:
import {sql} from 'db';
// ...Theory Killer: Serverless
But what if you deploy on Vercel (or another serverless platform)? Here, pooling doesn’t behave as expected—because serverless functions don’t keep connections alive between invocations. Plus, even the different behaviour is non-deterministic, so you can’t really “plan” for it.
In Vercel’s Fluid Compute (enabled by default for new projects), this can work:
If traffic is low and requests arrive one at a time, the platform may reuse the same “warm” instance, so your singleton pool survives across requests. Or more simple: You can share warm instances of this singleton.
The problem: there’s absolutely no guarantee this will happen. Vercel might scale up as many shared singletons as it deems necessary—this is called autoscaling.
While there’s no determinism, I can explain when/how it typically occurs:
With the above setup, one request uses the first shared instance. If you wait 10 seconds and make another request, it will very likely reuse that same singleton. With minimal traffic, it simply maintains what exists—an unusual but possible scenario.
However, in more common cases, when traffic bursts occur (not millions or hundreds of requests, but around 10 concurrent requests), Vercel mitigates that burst by creating additional shared instances:
Generally, this autoscaling feature is excellent—except for databases.
This means you end up with multiple singletons, and if those singletons are pooling connections, you have multiple pools with no guarantee that the open connections are actually being utilized efficiently.
Jökull Solberg summarized this behavior well in his blog post:
This assumption broke down during scraping traffic with bursts of 1000 simultaneous requests. Even though Fluid reuses workers, it still scales up to handle incoming load — there’s no guarantee that a single module-level pool will serve all requests. Jökull Sólberg
The illusion of controlling this behavior by building a clever solution
You cannot control when your serverless provider reuses an instance or creates new ones. Period. Don’t attempt to develop clever solutions to free up connections in existing instances by making those instances communicate with each other—you’ll create a nightmare just for connecting to a database, and you won’t be able to manage that complexity.
Solving with one direct connection at a time?
One approach to solving this problem is creating one direct database connection per request and ensuring the connection is released when finished:
const sql = postgres(DIRECT_CONNECTION_URL, {max:1});
sql`SELECT 1`
sql.end();This prevents connection leaks but creates a bottleneck: if your database allows 60 connections maximum and you have 60 concurrent requests, the next request will fail to get a connection.
To address this, you could implement wait-and-retry logic:
async function callQuery(maxTriesThenFail: number) {
try {
const result = await sql`SELECT 1`;
console.log('DB connection succeeded');
return result;
} catch (err) {
// retry
if (--maxTriesThenFail < 1) {
throw err;
}
await setTimeout(200);
return callQuery(maxTriesThenFail);
}
}This can work but you’re still struggling a quite narrow count of connections. Let’s examine better solutions next.
1. Solving connection problems with Transaction Pooling
When you combine the previous “one-connection-per-function” approach with transaction-based pooling, you can handle significantly more connections. In Supabases Micro instance, that’s 140 connections more. Quite something.
What is Transaction pooling?
Transaction pooling (typically implemented with pgbouncer) involves connecting to a dedicated pooler instead of directly to the database. It creates multiple connection slots from fewer actual database connections by managing those slots efficiently.
For example, Supabase’s Micro plan provides 60 direct database connections but 200 connections when using their Transaction Pooler endpoint. This significantly reduces the bottleneck pain, especially since pgbouncer queues incoming requests when there is no resource available at the time to handle it.
However, this still doesn’t guarantee your request will execute. You would still need to implement failover logic to detect when queries fail due to connection exhaustion.
One connection per request is still bad, even with Transaction Pooling
Now comes a tricky part. We already said that we can’t trust that Vercel shares an instance of our db connections. But if it can, it will. Not so helpful, is it?
Yet here is a tricky fact: Using shared instances is much faster than reconnecting, even with the transaction pooler at the endpoint.
Whilst a fresh connection to the Transaction Pooler with a simple query came with ~1.2sec / req (total, 0.5sec for the query itself), a reused connection, depending on the load, only took ~0.3sec.
Okay, so what to do now?
Well, I’m sorry to state this but for reliability, you’ll have to take the bite from that sour apple and combine reconnect and retry.
I found it to be the only reliable source of preventing connection failure way above pooler connection limit (e.g. 2000 queries at 40 pooler connections).
Here’s the code I’ve used to juggle connections reliably:
import { Client } from "pg";
import { setTimeout } from "timers/promises";
export const retry = async <T>(
retryFunction: () => Promise<T>,
max: number = 5,
waitTime: number = 1000,
name?: string,
): Promise<T> => {
try {
const result = await retryFunction();
return result;
} catch (e) {
if (max > 0) {
await setTimeout(waitTime);
if (name) {
console.info("@retry=", name);
}
return retry(retryFunction, max - 1, waitTime);
} else {
throw e;
}
}
};
export const runWithClient = async <T>(
runner: (client: Client) => Promise<T>,
) => {
const client = await retry(
async () => {
const c = new Client(process.env.TRANSACTION_POOLER_URL);
await c.connect();
return c;
},
5,
1000,
"retry-conn",
);
// await retry(() => c.connect());
const r = await retry(() => runner(client));
await client.end();
return r;
};
import { runWithClient } from './db';
export async function GET() {
try {
const res = await runWithClient((c) => {
return c.query("SELECT * FROM teams LIMIT 1");
});
return Response.json(res.rows[0]);
} catch {
return new Response('failed', { status: 500 });
}
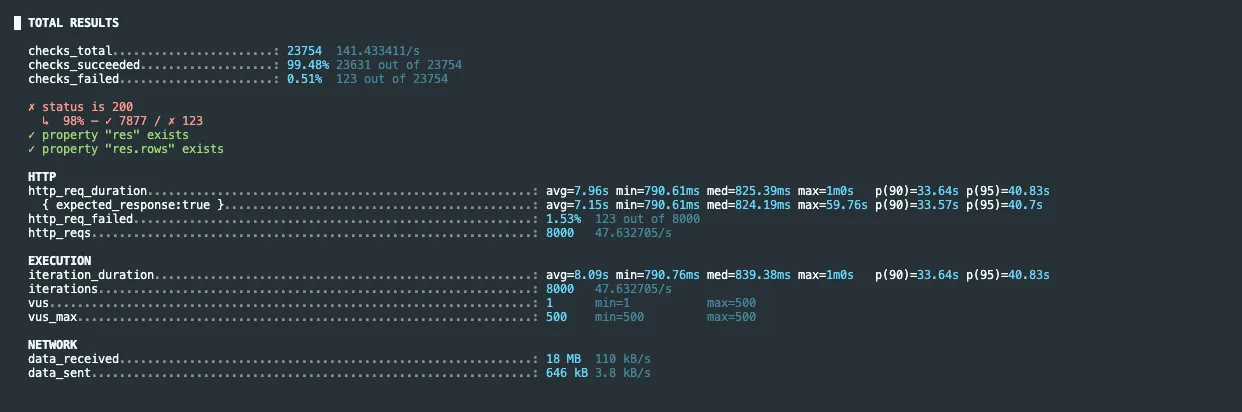
}Even a run with 4200 requests didn’t have one single point of failure with this method, pretty impressive right?
With a test of 500 virtual users, 8k requests, notably only 200 pooler connections available, it took quite a lot of time, but only 1.53% of the requests actually failed as you can see here:
Update (July 2nd 2025): This solution not only works well but seems to align with how CF proposes connections in serverless workers: https://developers.cloudflare.com/hyperdrive/examples/connect-to-postgres/#driver-examples . The difference is that my solution is more forgiving.
You might want to deploy your own Pooler
Supabase allows to scale your instance, which also scales pooler limits. For instance, the most expensive 16xl instance supports up to 12,000 connections—substantially more capacity in terms of actual requests (one connection can handle multiple queries per second).
However, scaling the instance solely for connection limits might be expensive. In his article, Jökull Sólberg chose to deploy his own pgbouncer on Fly.io connected to Supabase:
My solution: I deployed my own PgBouncer proxy on Fly.io. It runs in the same AWS region as Supabase (us-east-1) and Vercel (Ashburn/IAD). It accepts tens of thousands of connections from Vercel and fans them into a much smaller number of pooled connections to Supabase. This allows me to independently scale app layer concurrency and DB concurrency. Jökull Sólberg
You won’t necessarily handle more concurrent requests, but you’ll ensure requests don’t get lost with this high connection capacity.
2. Avoiding connection problems with an API layer
If your serverless functions make API requests instead of database queries, the only limitation is the API server capacity. I mean, sure thing, also an API has its limitations, everything has. But your serverless application wouldn’t have to deal with that. It would only deal with the response from it.
Some developers prefer Supabase’s Data API Layer (PostgREST) — I do. Others prefer connecting to the database via an ORM like Drizzle. Interestingly, the latter often assume they’ll encounter fewer issues with direct database connections through an ORM.
I’m inclined to say they usually experience more problems, also looking at the clients that I’ve worked with. Using the Data API not only standardizes API requests with Supabase but also simplifies connection handling by removing that piece of troubleshooting top of your mind.
For critical thinkers, here’s the obvious question: “Isn’t the Data API Layer limited as well?” Yes, it is. The Data API has its own pooler system. However, it can naturally handle up to 1,000 requests per connection, as confirmed by the author Steve (benchmarks available here: https://github.com/supabase/benchmarks/issues/9#issuecomment-1299000244). This should be quite sufficient to start with even for larger requests and scaling vertically with more users isn’t a big deal then.
It’s also worth mentioning that the Data API of Supabase neatly integrates with having additional database read replicas - something that you would have to manage on your own with a direct connection, yet another added complexity.
Wait, you forgot about Session Pooling?
Session pooling exists and Supabase offers it as well, but it’s worth noting that session pooling essentially provides 1:1 direct database connections. The difference from direct connections is simply: you have more of them because the pooler deployed on Supabase does the pooling job for you.
However, the general problems that come with direct connections in Serverless are the same.
That’s enough reason for me to not use it. Additionally, with Supabases Session Pooling Endpoint, I also didn’t manage to connect with any other user than postgres.
What about the serverless db Neon
Before I ran this research, I’ve never used Neon before. That also makes, whatever I say in this section, only bound to this small context, so I can’t judge Neon “in general”. Hence, be aware of that when you look at these stats and don’t take just my word for it.
I’m a huge Supabase fan and it’s a great technology to run everything you need - plus, it’s Open Source, so you’re never locked in. Also, it has to be said that we are not comparing Neon with Supabase here as this no fair comparison - they serve different needs beyond the database.
We are only comparing the read performance of Neon Free with the @vercel/postgres package against a Micro Supabase instance on Vercel.
Neon on Vercel
In terms of just Postgres, Neon does seem to shine in this test. In fact, it amazed me. I created a Neon database in the same region as my Supabase one to allow for the same delays.
The results below are all end-to-end, so browser-to-server-to-browser.
Speedwise, Neon was often a little bit faster but let’s be honest, the user doesn’t care much if it’s 0.3sec or 0.45sec for most of the data-related tasks, especially since those are averages
and both Supabase and Neon were able to deliver at 0.3sec-ish. But still, Neon reliably was faster at all times.
However, there is a much more tremendous difference between those two in terms of reliability of concurrent requests and it’s not the speed per request. It’s the amount of requests.
While, with proper configuration, I could have 0.3sec per request, end-to-end with Supabase/Postgres, the usage of @vercel/postgres
in combination with a Neon database was most likely always 0.3sec or below.
It comes with zero-configuration out of the box and out of curiosity I checked the max_connections settings as well as the actual factually made connections
whilst firing a lot of requests towards Neon.
| Concurrent Requests | Total time spent | Failed Requests | |
|---|---|---|---|
| Supabase Micro (TP) | 300 (500% more than available) | 6,6sec initial | 100 (33%) |
| Neon Free | 300 (33% of Connections, although only 5% used) | 4,2sec initial | 0 |
| Supabase Micro (TP) | 1000 (1600%) | 3,6sec 2nd burst | 732 (73%) |
| Neon Free | 1000 (110%, although only 7% used) | 1,2sec 2nd burst | 0 |
| Neon Free | 10000 (1100%) | 9,4sec 2nd burst | 2398 (23%) |
The above table results with regards to Supabase are somewhat expected - without using a retry mechanism - because of the connection limits (200 pooled connections).
At the same time however, it’s impressive that Neon only had a few failures even going way beyond their connection limit. Handling about 8k concurrent requests in a free plan successfully is indeed a masterpiece of performance.
The obvious downside of Neon even if you just need Postgres: Not really open-source and potentially caveats due to its nature of not being a pure Postgres.
A sligthly more fair comparison of Supabase/Neon
To have some comparison without Serverless, I also did a pgbench on the performance of the same query, just measuring
average query speed:
Avg Query Speed (SELECT * FROM teams LIMIT 1) | Type | |
|---|---|---|
| Supabase Micro (TP) | 48ms | pgbouncer |
| Supabase Micro (TP) | 50ms | Supavisor |
| Neon Free | 33ms |
In both cases, query performance can be much more efficient if using a proper mechanisms like Pooling, just a side-note. The above stats should not be your basis for database decisions.
But let’s get back to the connection congestion problem now.
Vercel proposes a solution to connecting to databases - I don’t recommend it
Only because something is stated by somehting/someone well-known on the internet, it can still be wrong. Albert Einstein
Jokes aside. In this Link, Vercel proposes the following mechanism to work with databases and serverless Functions on Fluid compute:
import { Pool } from 'pg';
const pool = new Pool({
connectionString: process.env.DATABASE_URL,
});
export async function GET() {
const client = await pool.connect();
try {
const { rows } = await client.query('SELECT NOW()');
res.status(200).json({ time: rows[0] });
} finally {
client.release();
}
}Yes, Vercel explicitly does not use a shared / external file but tries to make use of “warm” functions. That means, if you define pool outside of the Function handler,
Vercel can deliver a subsequent request with the same function executing a fresh handler but reusing the same pool instance.
This works super-well for all requests that succeed - when they succeed.
This solution essentially throttles your database more or less at the exact connection pooler count (so 200 in my case). Anything beyond that fails.
Even the retry-solution from above doesn’t work wonders here. This Vercel-proposed solution slowly but effectively seems to leak connections and with multiple concurrent requests bursts, I reached more and more failure points where 90-100% of requests failed. That’s due to the suspending nature of the instances used by Vercel, connections are held for longer and not released back to the pool when suspending.
If using a real direct database connection (as one could assume from Vercels link), already the 2nd burst over connection limit has 100% failure rate if it doesn’t hit the same pool by accident.
Somewhat surprising was the fact that when I created the pool in its own file as “shared file”, I wasn’t able to create connection leakage
and the requests/queries that were successfull were pretty fast, up to 0.12sec. However, even with a retry function, it failed 1555 of 2000, so ~77% failure rate.
Conclusion and Recommendation
If you use a normal Postgres (e.g. Supabase or simply your self-deployed Postgres), use pgbouncer with transaction pooling and timeouts as well as a retry-method.
If there’s congestion happening, it’s resolved in a reasonable amount of time due to the timeouts provided.
Also, make sure to set a sensible statement_timeout in Postgres itself. For Supabase, the postgres user timeout is usually set to 2min.
That’s quite long and for most of the queries not required. I recommend creating a new database user e.g. app_user and set the statement_timeout for that user to 20sec max.
The postgres library (and the pg lib analogusly) also has settings like connect_timeout and idle_timeout - the default settings are too high. Adapt them to your needs as low as possible and
also decrease the amount of connections (in postgres it’s max) that the driver is allowed to open. In my retry sample above, I only allow 1 connection
per request to avoid clogging. As I said earlier: I exchange speed-bumps in favor of stability.
Whatever you do: Always keep the Design-for-Failure-Principle top of mind.
Do not use Direct Database connections or Session pooling as those are your best partners for accidentally clogging the database as you can’t control the serverless scaling behaviour.
The interesting aspect is that all effective solutions share the same characteristic: the executing database endpoint must not be serverless.
Whether you use the PostgREST API to fetch data, your own backend, pgbouncer, or Supavisor—all of them run as persistent servers, not as serverless functions, because it’s the only way to provide the reliability and stability required for database connections.